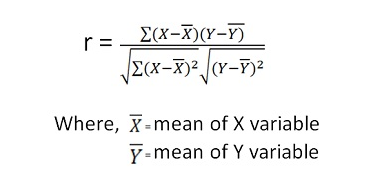A recommendation system recommends you products or items that can be of your interest or liking.
Mohammad Ibrahim Khan
Senior Associate - DSG
Why do we need a recommendation system ?
Let us take the simplest and the most relatable example of E-commerce giant, Amazon. When we shop at Amazon, it gives us the options of bundles and products that are usually bought along with the product you are currently going to buy. For example, if you are to buy a smartphone, it recommends you to buy a back cover for the product as well.
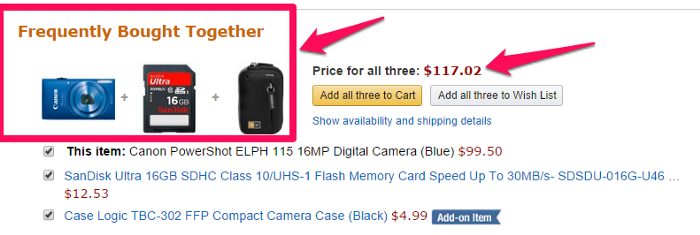
For a second let us think and try to figure out what Amazon is trying to do in the figure below:
What does a recommendation system do ?
A recommendation system recommends you products or items that can be of your interest or liking. Let’s take another example:
It’s quite easy to notice that they are trying to sell the equipment that is generally required for a camera (memory card and the case). Now, the main question is, how do they do it for millions of items listed on their website. This is where a recommendation system comes handy.
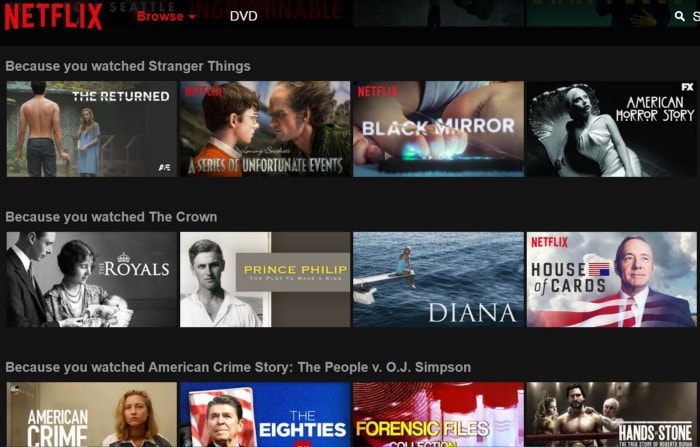
When we first set up our Netflix account, they ask us what our preferences are, which movie or TV show is most likely to be watched by us or what genre of movie is our favorite. So as the first layer of recommendation, Netflix gives us recommendations based on our input, it shows us movies or shows similar to the input that we had provided to it. Once we are a frequent user, it has gathered enough data and gives recommendations more accurately based on our preferences of genres, cast, star rating, and so on…
The ultimate aim here is to recommend a user with an item such that he will watch it or buy it(in the case of Amazon), this in turn makes sure that the user is engaged with the platform and the customer lifetime value(CLTV) is maintained.
Objective of this blog
By the end of this blog, one will have a basic understanding of how to approach towards building a recommendation system. To make things more lucid let us take an example and try building a Hotel recommendation system. In this process, we will cover data understanding and the algorithms that can be used to realize how a nascent recommendation engine is built. We will use analogies between diurnal used products like Amazon and Netflix to have a clearer understanding.
Understanding the data required for building a recommendation system
To build a recommendation system, we must be clear with the problem statement and the end objective to provide accurate recommendations. For example, consider the following scenarios:
Providing a user with a hotel recommendation based on his/her current search and historical behavior (giving a recommendation knowing that a user is looking for a hotel in Las Vegas and prefers hotels with casinos).
Providing a hotel recommendation based on the user’s historical behavior, targeting those users who are not actively engaged (searching) but can be incentivized towards making a booking by targeting through a relevant recommendation (a general recommendation can be based on metrics such as a user’s historical star rating preference or historical budget preference).
These are two different objectives, and hence, the approach towards achieving both of them is different.
One must be aware of what type of data is available and also needs to know how to leverage that data to proceed towards building a recommendation engine.
There are two types of data which are of importance in our use case:
Explicit Data:
Explicit signals or input is where a user directly gives feedback to a particular item/product. This can be star values, say in the range of 1 to 5 or just a binary 1(like) and 0(dislike). For example, when we rate an item on Amazon or when we rate a movie on IMDb, these are explicit signals where we are directly giving our feedback towards an item. One thing to keep in mind is that we should be aware that each and every individual is not the same, i.e. for an Item X, User A, and User B can have different ratings. User A can be generous with his ratings and can give a rating of 5 stars whereas, User B is a critic and gives Item X 3.5 stars and gives 5 stars only for exceptional Items.
Replicating the example for our Hotel recommendation use case can be summarized like, the filters that a user applies while searching for a Hotel, say, filters like swimming pool or WiFi are explicit signals, here the user is explicitly saying that he is interested in properties which have WiFi and a swimming pool.
Additionally, the explicit data is sparse in most of the cases, as it is not ideally possible for a user to give ratings to each and every item. Logically thinking, I would not have seen each and every movie on Netflix and hence can only provide feedback for the set of movies that I have seen. These ratings reflect how much a user likes or approves of an item.
Implicit Data:
Implicit signals are obtained by capturing a user’s interaction with the item. This can be a continuous value, like the number of times a user has clicked on an item or the number of times a user has watched an Action movie or Binary, similar to just clicked or not clicked. For example, while scrolling through amazon.com the amount of time spent viewing an item or the number of times you have clicked the item can act as implicit feedback.
Drawing parallels for hotel recommendations with implicit signals can be understood as follows. Consider that we have the historical hotel bookings of a user A, and we see that in the 4 out of 5 bookings made by the user, it was a property that was near the beach. This can act as an implicit signal where we can say that user A prefers hotels near the beach.
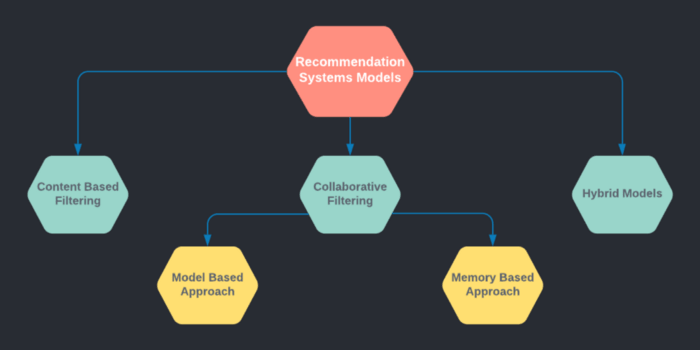
Types of Recommendation Systems
Let us take a specific example given below to further explain the recommendation models:
While making a hotel recommendation system, we have the user’s explicit and implicit signals. However, we do not have all the signals for all the users, for a set of users E, we have explicit signals and for a set of users I, we have implicit signals.
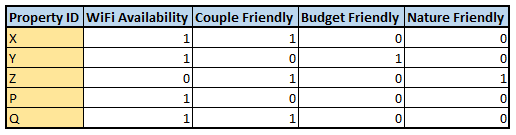
Further, let us assume that a hotel property has the following attributes:
WiFi Availability, Couple Friendly, Budget Friendly and Nature Friendly (closer to nature)
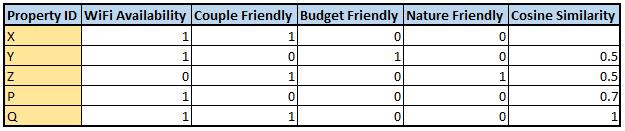
For simplicity, let us assume that these are flags, such that if a property A has WiFi in it, the WiFi availability column will be 1. Hence our hotels data will look something like the following:
Let us name this table as Hotel_Type for further use
Content Based Filtering:
This technique is used when explicit signals are provided by the user or when we have the user and item attributes and the interaction of the user with that item. The objective here is to show items/products which are similar to the item/product that a person has already purchased or shows a liking for, or in another case, show a product to a user where he explicitly says that he is looking for something in particular. Taking our example, consider that you are booking a hotel from xyz.com, you apply filters for couple-friendly properties, here you are explicitly saying that you are looking for a couple-friendly property and hence, xyz.com will show you properties that are couple friendly. Similarly, while providing recommendations, if we have explicit signals from a user we try to get the best match for that signal with the list of items that we have and provide recommendations accordingly.
Model Algorithms:
Cosine Similarity: It is a measure of similarity
between two non-zero vectors. The values range from 0 to 1.
Cosine Similarity is used as a measure of similarity between two non-zero vectors. Here the vectors can be both user or item based.
Let us take an example, Assume that a user A has specifically shown interest towards property X from the hotel_type table (the user has previously booked the property or has searched for the property X multiple times recently), we now have to recommend him properties that are similar to property X. To do so, we are going to find the similarity between property X and the rest of the properties in the table.
We can clearly see that property Q has the highest similarity with property X and followed by property P. So if we are to recommend a property to user A, we will recommend him property Q knowing that he has a preference for property X.
Pearson Correlation: It is a measure of linear correlation between two variables. The values range from -1 to 1.
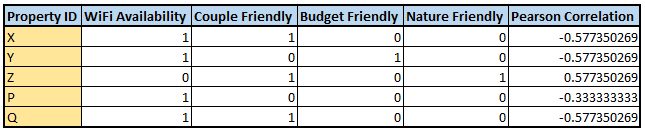
Let us take an example where we are getting explicit input from the user where the user is shown the 4 categories (WiFi, Budget, Couple, Nature). The user has the option to provide his input by selecting as many as he wants, he can even select none. Considering the case when a user B has selected at least one of the 4 options. Now, assume user B’s input looks like the following:
While one can say that we can use cosine similarity in this case by just filling in the null values as 0. However, it is not advised to do so since, cosine similarity assumes the 0’s as a negative preference and in this explicit signal we cannot for sure say that user B is not looking for a couple friendly or a budget friendly property just because the user has not given an input in that field.
Hence, to avoid this, we use Pearson correlation and the output of the similarity measuring technique would look like the following:
We can see that property Z is highly correlated to user B’s explicit signal and hence, we will provide Z as a recommendation for user B.
So, for the set of users E (explicitly proving us their preference) we will use Pearson Correlation and for the set of users I (implicitly telling us that he/she is looking for a property with a certain set of attributes), we will use Cosine Similarity.
Note: A user’s explicit signal is always preferred over an implicit signal. For example, in the past, I have only booked hotels in the urban areas, however, now I want to book a hotel near the beach (nature friendly). In my explicit search, I specify this, but if you are making an implicit signal from my past bookings you will see that I do not prefer hotels near the beach and would recommend me hotels in the city. In conclusion, Pearson correlation and Cosine similarity are the most widely used similarity techniques, however, we need to always use the correct similarity measuring technique as per our use case. More information on different types of similarity techniques can be found here.
Collaborative Filtering:
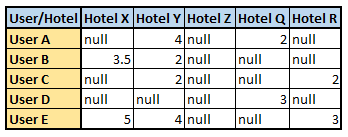
This modeling technique is used by leveraging user-item interaction. Here, we try to match or group similar users and recommend based on the preferences of similar users. Let us consider a user-item interaction matrix (rating matrix) where we have the hotel rating a user has given a particular hotel:
Rating Matrix
Now let us compare user A and user E, we can see that they both have similar tastes and have rated Hotel Y as 4, seeing this let us assume that user A will rate Hotel X as 5 and hotel R as 3. Hence, we can give a recommendation of hotel X to user A by noticing the similarity between user A and user E (considering that he will like Hotel X and rate it 5).
So, if we are provided with the interaction of a user with an item where the user has given feedback towards the item, we can use collaborative filtering (for example, the rating matrix). Explicit ratings such as star rating
given by the user or Implicit signals such as a flag if the user has booked a property or contrary of user-item interaction.
Model Algorithms:
Memory and Model-Based Approach are the two types of techniques to implement collaborative filtering. The key difference between the two is that in the memory-based approach we do not use parametric machine learning models.
Memory-Based Approach: It can be divided into two subdivisions, user-item filtering, and item-item filtering. In the user-item approach, we identify clusters of similar users and utilize the interaction of a particular user in that cluster to predict the interaction of the whole cluster. For example, to predict the rating user C gives to a hotel X, we will take a weighted sum of hotel X’s rating by the other users, here weight is the similarity number between user X and the other users. Adjusted cosine similarity can also be used to remove the difference in the nature of individuals, which brings critics and the general public on the same scale.
Item-item filtering is similar to user-item filtering, but here we take an item and see the users that liked that item and find other sets of items that those set of users or similar users also liked. It takes items, finds similar items, and outputs those items as recommendations.
Model-Based Approach: In this technique, we use machine learning models to predict the rating for an item that could have been given by a user and hence, provide recommendations.
Several ML models that are used, to name a few, Matrix factorization, SVD (singular value decomposition), ALS, and SVD++. Some also use neural networks, decision trees, and latent factor models to enhance the results. We will delve into Matrix Factorization below.
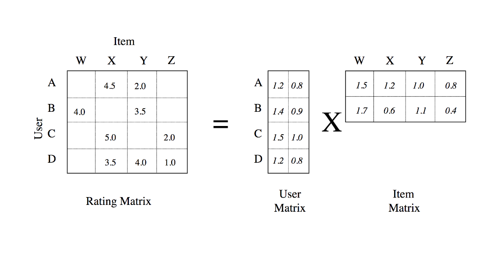
Matrix Factorization:
In matrix factorization, the goal is to complete the matrix and fill in the null values in the rating matrix.
The preferences of the users are identified by a small number of hidden features of the user and items. Here there are two hidden feature vectors for users(user matrix 4×2) and items(item matrix 2×4). Once we multiply the user and item matrix back together, we get back our ratings matrix with null values replaced by predicted values. Once we get the predicted values, we can recommend an Item with the highest rating for a user (not considering the items already interacted with).
Note: Here we are not providing any feature vector for the users or the items, the computation decomposes and creates vectors on its own and, finally, predicts by filling in the null values.
If we have user demographics information and user’s features and preference information and item features, we can use SVD++ where we can pass users and item feature vectors as well to get the best recommendation results.
Hybrid Models:
The hybrid model combines multiple models/algorithms to build a recommendation system. To improve the effectiveness of the recommendation, we can combine collaborative filtering and content-based filtering giving appropriate weights to the individual models and finally using this hybrid system to give out a recommendation.
For example, we can combine the results of the following by giving weights:
Using Matrix factorization (collaborative filtering) on ratings matrix to match similar users and predict a rating for the user-item pair.
Using Pearson correlation (content-based filtering) to find similarity between users who provide explicit filters and the hotels with feature vectors.
The combined results can be used to provide recommendations to users.
Conclusion:
Building a recommendation system highly depends on the end objective and the data we have at hand. Understanding the algorithms and knowing which one to use to get recommendations plays a vital role in building a suitable recommendation system. Additionally, a sound recommendation system also uses multiple algorithms and combines the results to provide the final recommendations.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.