Natural Language Inferencing (NLI) Task: Demonstration Using Kaggle Dataset
Natural Language Inferencing (NLI) task is one of the most important subsets of Natural Language Processing (NLP) which has seen a series of development in recent years.
Akasapu Hemanthika
Senior Associate - DSA
Natural Language Inferencing (NLI) task is one of the most important subsets of Natural Language Processing (NLP) which has seen a series of development in recent years. There are standard benchmark publicly available datasets like Stanford Natural Language Inference (SNLI) Corpus, Multi-Genre NLI (MultiNLI) Corpus, etc. which are dedicated to NLI tasks. Few state-of-the-art models trained on these datasets possess decent accuracy. In this blog I will start with briefing the reader about NLI terminologies, applications of NLI, NLI state-of-the-art model architectures and eventually demonstrate the NLI task using Kaggle Contradictory My Dear Watson Challenge Dataset by the end.
Prerequisites:
Basics of NLP
Moderate Python coding
What is NLI?
Natural Language Inference which is also known as Recognizing Textual Entailment (RTE) is a task of determining whether the given “hypothesis” and “premise” logically follow (entailment) or unfollow (contradiction) or are undetermined (neutral) to each other. For example, let us consider hypothesis as “The game is played by only males” and premise as “Female players are playing the game”. The task of NLI model is to predict whether the two sentences are either entailment, contradiction, or neutral. In this case, it is a contradiction.
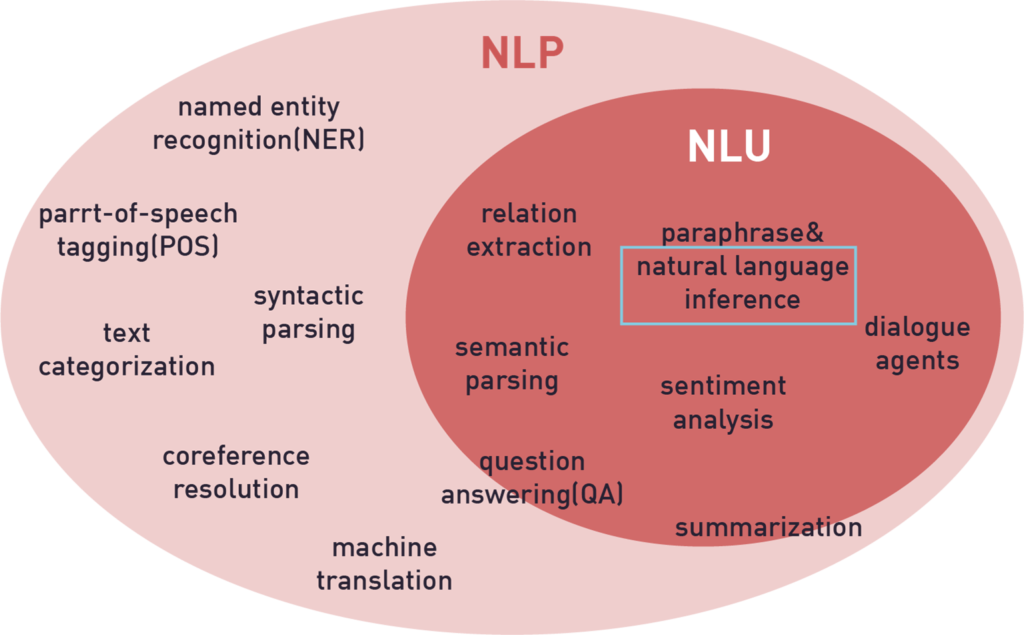
How NLI is different from NLP?
The main difference between NLP and NLI is that NLP is a broader set that contains two subsets Natural Language Understanding (NLU) and Natural Language Generation (NLG). We are more concerned about NLU as NLI comes under this. NLU is basically making the computer capable of comprehending what the given text block represents. NLI, which comes under NLU is the task of understanding the given two statements and categorizing them either as entailment, contradiction, or neutral sentences. When dealing with data most of the NLP tasks include pre-processing steps like removing stop words, special characters, etc. But in case of NLI, one has to just provide the model with two sentences. The model then processes the data itself and outputs the relationship between the two sentences.
NLI is been used in many domains like banking, retail, finance, etc. It is widely used in cases where there is a requirement to check if generated or obtained result from the end-user follows the hypothesis. One of the use cases includes automatic auditing tasks. NLI can replace human auditing to some extent by comparing if sentences in generated document entail with the reference documents.
Models used to Demonstrate NLI Task
In this blog, I have demonstrated the NLI task using two models: RoBERTa and XLM-RoBERTa. Let us understand these models in this section.
In order to understand RoBERTa model, one should have a brief knowledge about BERT model.
BERT
Bidirectional Encoder Representation Transformers (BERT) was published by Google AI researchers in 2018. It has shown state-of-the-art results in many NLP tasks like question and answering, NLI task etc. It is basically an encoder stack of transformer architecture. It has two versions BERT base and BERT large. BERT base has 12 layers in its encoder stack and 110M total parameters whereas BERT large has 24 layers and 340M total parameters.
BERT pre-training consists of two tasks:
Masked Language Model (MLM)
Next Sentence Prediction (NSP)
Masked LM
In the input sequence sent to the model as input, randomly 15% of the words are masked and the model is tasked to predict these masks by understanding the context from unmasked words at the end of training. This helps model in understanding the context of the sentence.
Next Sentence Prediction
Model is fed with two-sentence pairs as input. In this task, a model must predict at the end of training whether the sentences follow or unfollow each other. This helps in understanding the relationship between two sentences which is the major objective for tasks like question and answering, NLI, etc.
Both the tasks are executed simultaneously while training.
Model Input
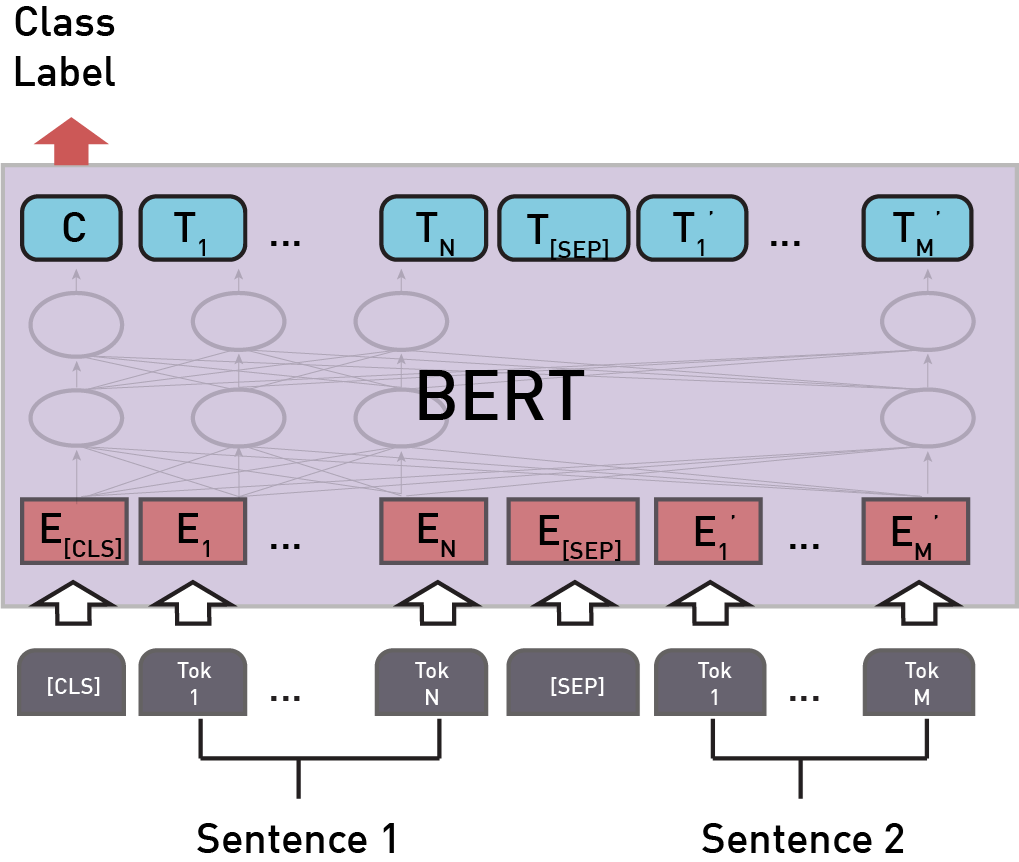
Input to the BERT model is a sequence of tokens that are converted to embeddings. Each token embedding is a combination of 3 embeddings.
Figure 2: BERT input representation [1]
Token Embeddings – These are word embeddings from WordPiece token vocabulary.
Segment Embeddings – As BERT model takes pair of sentences as input, in order to help model distinguish the embeddings from different sentences these embeddings are used. In the above picture, EA represents embeddings of sentence A while EB represents embeddings from sentence B.
Position Embeddings – In order to capture “sequence” or “order” information these embeddings are used to express the position of words in a sentence.
Model Output
The output of BERT model has the same no. of tokens as input with additional classification token which gives the classification results ie. whether sentence B follows sentence A or not.
Figure 3: Pre-training procedure of BERT [1]
Fine-Tuning BERT
A pre-trained BERT model can be fine-tuned to achieve a specific task on specific data. Fine-tuning uses same architecture as the pre-trained model only an additional output layer is added depending on the task. In case of NLI task classification token is fed into the output classification layer which determines the probabilities of entailment, contradiction, and neutral classes.
Figure 4: Illustration for BERT fine-tuning on sentence pair specific tasks like MNLI, QQP, QNLI, RTE, SWAG etc. [1]
BERT GLUE Task Results
Figure 5: GLUE test results [1]
As you can see in figure 4, BERT outperforms all the previous models on GLUE tests.
RoBERTa
Robustly Optimised BERT Pre-training Approach (RoBERTa) was proposed by Facebook researchers. They found with a much more robustly pre-training BERT model it can still perform better on GLUE tasks. RoBERTa model is a BERT model with modified pre-training approach.
Below are the few changes incorporated in RoBERTa model when compared to BERT model.
Data – RoBERTa model is trained using much more data when compared to BERT. It is trained on 160GB uncompressed data.
Static vs Dynamic Masking – In BERT model, data was masked only once during pre-processing which results in single static masks. These masks are used for all the iterations while training. In contrast, data used for RoBERTa training was duplicated 10 times with 10 different mask patterns and was trained over 40 epochs. This means a single mask pattern is used only in 4 epochs. This is static masking. While in dynamic masking different mask pattern is generated for every epoch during training.
Figure 6: Static vs Dynamic masking results [2]
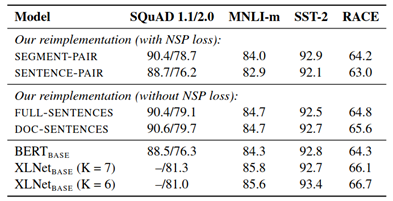
3. Removal of Next Sentence Prediction (NSP) objective – Researches have found that removing NSP loss significantly improved the model performance on GLUE tasks.
Figure 7: Model results comparison when different input formats are used [2]
4. Trained on Large Batch Sizes – Training model on large batch sizes improved the model accuracy.
Figure 8: Model results when trained with different batch sizes [2]
5. Tokenization – RoBERTa uses a byte-level Byte-Pair Encoding (BPE) encoding scheme with a containing 50K vocabulary in contrast to BERT’s character-level BPE with a 30K vocabulary.
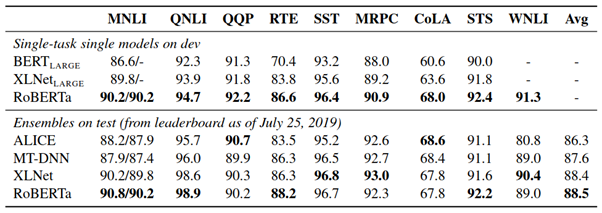
Figure 9: RoBERTa results on GLUE tasks. [2]
RoBERTa Results on GLUE Tasks
RoBERTa clearly outperforms when compared to previous models.
XLM-RoBERTa
XLM-R is a large multilingual model trained on 100 different languages. It is basically an update to Facebook XLM-100 model which is also trained in 100 different languages. It uses the same training procedure as RoBERTa model which used only Masked Language Model (MLM) technique without using Next Sentence Prediction (NSP) technique.
Noticeable changes in XLM-R model are:
Data – XLM-R model is trained on large cleaned CommonCrawl data scaled up to 2.5TB which is a way larger than Wiki-100 corpus which was used in training other multilingual models.
Vocabulary – XLM-R vocabulary contains 250k tokens in contrast to RoBERTa which has 50k tokens in its vocabulary. It uses one large shared Sentence Piece Model (SPM) to tokenize words of all languages instead of XLM-100 model which uses different tokenizers for different languages. XLM-R authors assume that similar words across all the languages have similar representation in space.
XLM-R is self-supervised, whereas XLM-100 is supervised model. XLM-R samples stream of text from each language and trains the model to predict masked tokens. XLM-100 model required parallel sentences (sentences that have same meaning) in two different languages as input which is a supervised method.
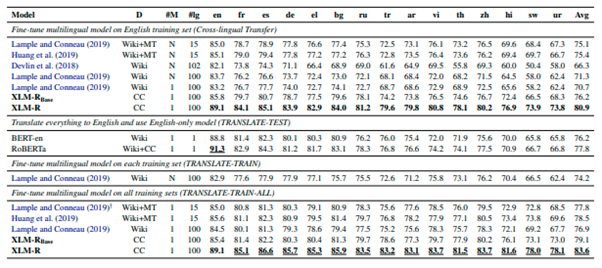
XLM-R Results on Cross-Lingual-Classification on XNLI dataset
Figure 10: XLM-R results on XNLI dataset. [3]
XLM-R is now the state-of-the-art multilingual model which outperforms all the previous multi-language models.
Demonstration of NLI Task Using Kaggle Dataset
In this section, we will implement the NLI task using Kaggle dataset.
Kaggle has launched Contradictory My Dear Watson challenge to detect contradiction and entailment in multilingual text. It has shared a training and validation dataset that contains 12120 and 5195 text pairs respectively. This dataset contains textual pairs from 15 different languages – Arabic, Bulgarian, Chinese, German, Greek, English, Spanish, French, Hindi, Russian, Swahili, Thai, Turkish, Urdu, and Vietnamese. Sentence pairs are classified into three classes entailment (0), neutral (1), and contradiction (2).
We will be using the training dataset of this challenge to demonstrate the NLI task. One can run the following code blocks using Google Colab and can download a dataset from this link.
Code Flow
1. Install transformers library
!pip install transformers
2. Load XLM-RoBERTa model –
Since our dataset contains multilingual text, we will be using XLM-R model for checking the accuracy on training dataset.
from transformers import AutoModelForSequenceClassification, AutoTokenizer xlmr= AutoModelForSequenceClassification.from_pretrained(‘joeddav/xlm-roberta-large-xnli’) tokenizer = AutoTokenizer.from_pretrained(‘joeddav/xlm-roberta-large-xnli’)
3. Load training dataset –
import pandas as pd train_data = pd.read_csv(<dataset path>) train_data.head(3)
4. XLM-R model classes –
Before going further do a sanity check to confirm if the model classes notation and the dataset classes notation is same
We can see that the model classes notation and Kaggle dataset classes notation (entailment (0), neutral (1), and contradiction (2)) is different. Therefore, change the training dataset classes notation to match with model.
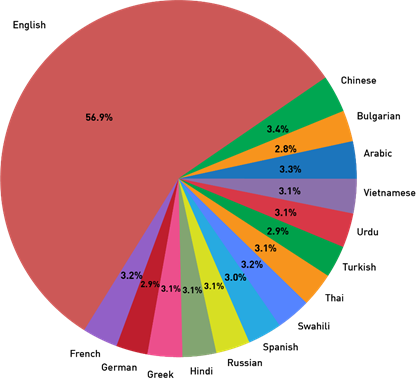
Check the distribution of training data based on language
train_data_lang = train_data.groupby(‘language’).count().reset_index()[[‘language’,’id’]] # plot pie chart import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(10,10)) plt.pie(train_data_lang[‘id’], labels = train_data_lang[‘language’], autopct=’%1.1f%%‘) plt.title(‘Distribution of Train data based on Language’) plt.show()
We can see that English constitutes to more than 50% of the training data.
7. Sample data creation –
Since training data has 12120 textual pairs, evaluating all the pairs would be time-consuming. Therefore, we will create a sample data out of training data which will be a representative sampling ie. sample data created will have the same distribution of text pairs based on language as of the training data.
# create a column which tells how many random rows should be extracted for each language train_data_lang[‘sample_count’] = train_data_lang[‘id’]/10 # sample data sample_train_data = pd.DataFrame(columns = train_data.columns) for i in range(len(train_data_lang)): df = train_data[train_data[‘language’] == train_data_lang[‘language’][i]] n = int(train_data_lang[‘sample_count’][i]) df = df.sample(n).reset_index(drop=True) sample_train_data = sample_train_data.append(df) sample_train_data = sample_train_data.reset_index(drop=True) # plot distribution of sample data based on language sample_train_data_lang = sample_train_data.groupby(‘language’).count().reset_index()[[‘language’,’id’]] plt.figure(figsize=(10,10)) plt.pie(sample_train_data_lang[‘id’], labels = sample_train_data_lang[‘language’], autopct=’%1.1f%%‘) plt.title(‘Distribution of Sample Train data based on Language’) plt.show()
We can see that sample data created and the training data have nearly same distribution of text pairs based on language.
8. Functions to get predictions from XLM-R model –
def get_tokens_xlmr_model(data): ”’ Function which creats tokens for the passed data using xlmr model input – Dataframe Output – list of tokens ”’ batch_tokens = [] for i in range(len(data)): tokens = tokenizer.encode(data[‘premise’][i], data[‘hypothesis’][i], return_tensors=’pt’, truncation_strategy=’only_first’) batch_tokens.append(tokens) return batch_tokens def get_predicts_xlmr_model(tokens): ”’ Function which creats predictions for the passed tokens using xlmr model input – list of tokens Output – list of predictions ”’ batch_predicts = [] for i in tokens: predict = xlmr(i)[0][0] predict = int(predict.argmax()) batch_predicts.append(predict) return batch_predicts
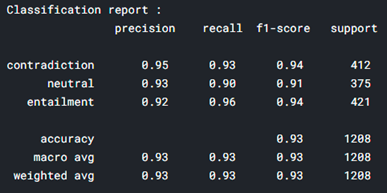
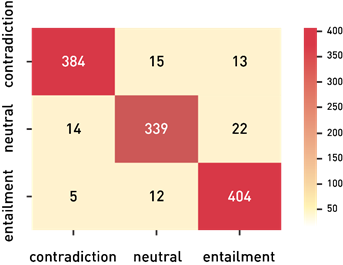
# plot the confusion matrix and classification report for original labels to the predicted labels import numpy as np import seaborn as sns from sklearn.metrics import classification_report sample_train_data[‘label’] = sample_train_data[‘label’].astype(str).astype(int) x = np.array(sample_train_data[‘label’]) y = np.array(sample_train_data_predictions) cm = np.zeros((3, 3), dtype=int) np.add.at(cm, [x, y], 1) sns.heatmap(cm,cmap=”YlGnBu”, annot=True, annot_kws={‘size’:16}, fmt=’g’, xticklabels=[‘contradiction’,’neutral’,’entailment’],
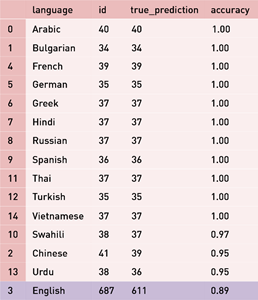
Except for English, rest of the languages are having accuracy greater than 94%. Therefore, use a different model for English pairs prediction to further improve accuracy.
12. RoBERTa model for English text pairs prediction –
14. Functions to get predictions from RoBERTa model –
def get_tokens_roberta(data): ”’ Function which generates tokens for the passed data using roberta model input – Dataframe Output – list of tokens ”’ batch_tokens = [] for i in range(len(data)): tokens = roberta.encode(data[‘premise’][i],data[‘hypothesis’][i]) batch_tokens.append(tokens) return batch_tokens def get_predictions_roberta(tokens): ”’ Function which generates predictions for the passed tokens using roberta model input – list of tokens Output – list of predictions ”’ batch_predictions = [] for i in range(len(tokens)): prediction = roberta.predict(‘mnli’, tokens[i]).argmax().item() batch_predictions.append(prediction) return batch_predictions
sample_train_data_en[‘prediction’] = sample_train_data_en_predictions # roberta model accuracy sample_train_data_en[‘true_prediction’] = np.where(sample_train_data_en[‘label’]==sample_train_data_en[‘prediction’], 1, 0) roberta_accuracy = round(sum(sample_train_data_en[‘true_prediction’])/len(sample_train_data_en), 2) print(“Accuracy of RoBERTa model {}“.format(roberta_accuracy))
Accuracy of RoBERTa model 0.92
Accuracy of English text pairs increased from 89% to 92%. Therefore, for predictions on test dataset of Kaggle challenge use RoBERTa for English pairs prediction and XLM-R for predictions of other language pairs.
By this approach, I was able to score 94.167% accuracy on the test dataset.
Conclusion
In this blog ,we have learned what NLI task is, how to achieve this using two state-of-the-art models. There are many more pre-trained models for achieving NLI tasks other than the models discussed in this blog. Few of them are language-specific like German BERT, French BERT, Finnish BERT, etc. multilingual models like Multilingual BERT, XLM-100, etc.
As future steps, one can further achieve task-specific accuracy by finetuning these models with specific data.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.