Making our Data Scientists and ML engineers more efficient (Part 2)
In the last post, we briefly touched upon the concept of MLOps and one of its elements, namely the Feature Store.
Vineet Kumar
Co-Founder, CEO US
In the last post, we briefly touched upon the concept of MLOps and one of its elements, namely the Feature Store. We intend to cover a few more interconnected topics that are key to successful ML implementations and realizing sustained business impact.
At Affine, we ensure that a lion’s share of our focus in a ML project is on:
Investing more time on building Great Features and Feature Stores (than ML algos – yes, please don’t frown upon this ? ).
Setting up Robust and Reproducible Data and ML Pipelines to ensure faster and accurate Re-training and Serving.
Following ML and Production Standard Coding Practices.
Incorporating Model Monitoring Modules to ensure that the model stays healthy.
Reserving the last hour of each business day on Documentation.
And last but not the least, Regularly reciting the Magic words – Automate, Automate, Automate! ?
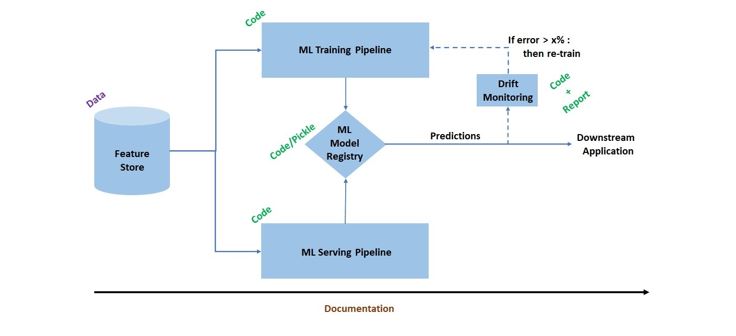
The following architecture is an attempt to simplify and encapsulate the above points:
This is the Utopian version of the ML architecture that every team aspires for. This approach attempts to address 3 aspects with respect to ML Training and Serving – Reproducibility, Continuous (or Inter-Connected-ness) and Collaboration.
Reproducibility of model artifacts/predictions – The ML components (Feature Engineering, Dataset Creation, ML tuning, Feature Contribution, etc.) should be build in such a way that it is simple to reproduce the output of each of those components seamlessly and accurately, at a later point in time. Now, from an application standpoint, this may be required for a root-case analysis (or model compliance) or re-trigger creation of ML pipeline on new dataset at a later point in time. However, equally importantly, if you can reproduce results accurately, it also guarantees that the ML pipeline (Data to ML training) is stable and robust! This also ultimately leads to reliable Model Serving.
Continuous Training aspect – This is known as Continuous Integration in the context of software engineering, and refers to automation of components like code merge, unit/regression testing, build, etc. to enable continuous delivery. A typical ML pipeline also comprises of several components (Feature Selection, Model Tuning, Feature Contribution, Model Validation, Model Serialization and finally Model Registry and Deployment). The Continuous aspect ensures that each module of our ML pipeline is fully automated and fully integrated (parameterized) with other modules, such that Data runs, Model Runs, and ML Deployment Runs happen seamlessly when the pipeline is re-triggered.
However, it all starts with “Collaboration” – Right Team and Right Mindset!
Before we delve deeper into each of these points, it is essential to touch upon one more topic – the need for a tightly-knit cross-functional team. It’s not pragmatic to expect the Data Scientists to handle all of the above aspects and the same is true for ML engineers. However, for a successful MLOps strategy, it’s important to get outside of our comfort zones, learn cross functional skills and collaborate closely. This means that the Data Scientists should learn to write production grade codes (modularization, testing, versioning, documentation, etc.) Similarly, the ML engineers should understand ML aspects like Feature Engineering and Model Selection to appreciate why these seemingly complex ML artifacts are critical in solving the business problem.
As for managing such a cross functional team of people that bring different niches, we need people who thrive in this knowledge-based ecosystem, where the stack keeps getting bigger every day. We need a ‘Jack of all Trades’, someone who knows a little bit of everything and possess the articulation skills to bring out the best from the team.
Getting the right cross functional team in place is the first (and unarguably the most important) piece of the puzzle. In the next article, we will go a bit deeper on each of the components described above. Please stay tuned…
About Author
Vineet is an industry veteran with nearly two decades of experience in the decision sciences sector. As a co-founder and chief solutions architect, Vineet and his team specialize in designing advanced analytics, AI, ML, and cloud solutions that enrich decision-making in Fortune 500 companies.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged.