Recently, AI has taken off the ground and has been bringing revolutionary changes in the industry. Its influence has been seen in many aspects of businesses. Many methodologies and algorithms with varying degrees of sophistication have been developed to address a variety of problems and designed to concentrate on the technical aspects of problem-solving. So, the emphasis lies on the coding part of the problem. However, any AI solution built to solve a problem consists of two parts – algorithm and data. The recent Data-centric AI campaign launched by Andrew Ng tries to emphasize that the models have achieved quite a good amount of sophistication and its high time we put more focus on the quality of data.
What is Data-Centric AI? And How it Helps Data-Driven Businesses?
Many AI algorithms with varying degrees of sophistication have been developed to address a variety of problems (eg. ResNet50, Inception, VGG16, etc. for image classification). Along with that, many methodologies have been developed to further finetune the model, such as regularization, cross-validation, etc. However, these techniques are built to focus on the technical side of problem-solving. So, the emphasis lies on the coding part of the problem.
The core idea of Data-centric AI is that that no amount of fine-tuning can fix bad data. Many of the models presently in use have high levels of complexity and can solve complex challenges. But in case, the data is incorrect or not clear enough, the model will learn as presented. Therefore, Andrew Ng proposes to focus more on data, a new methodology where the model is kept the same and the data is modified iteratively. Precisely, the model can be effectively notified using high-quality data. For this to work well, a proper and deep understanding of data is crucial. This is quite important because what helps to solve a business problem is a solid understanding of the problem itself. This will help us to systematically engineer data, and this can come only when there is clarity on data.
Characterizing the Aspects of High-Quality Data
For steeper insights we want refined and high-quality data, but how do we define it and what are the aspects for quality maintenance?
Consistency:
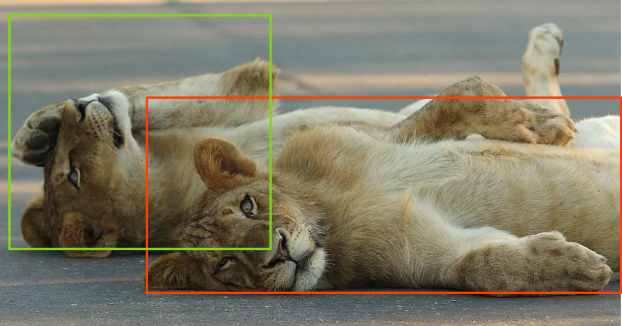
The data should be well defined. There should be clear guidelines and definitions for annotation and labeling. This could require inputs from multiple labelers and subject matter experts. For example, consider the following object detection problem. In the below figure, two lions are labeled very differently. Both ways are correct. However, the lack of a clear definition (how to label when there is another object in the foreground) led to different annotations. In more complex problems, this can be counterproductive. Therefore, it is essential to have clear guidelines.
Metadata:
Information such as time of creation, source, etc. are also important to determine the kind of data that is to be used. This helps us determine the principles on which the AI solution should be built. Ability to select data precisely can be beneficial while dealing with data drift and updating the model.
High quality of data is essential to develop a clearer understanding of the problem. It orients the decision-making process to be more data-driven rather than technique-driven. Proceeding with this solution requires closer collaboration with the subject matter experts. As a result, the solutions model can be developed in a way that allows Data Scientists to comprehend and manage how the model learns. It will almost certainly lead to the development of better solutions and an improvement in their performance.
In Data-centric AI, the philosophy is aimed at the best utilization of data which requires clear standards set up from the beginning i.e., the data collection. It can motivate businesses to standardize data collection and different processes across their value chains. This will streamline the data management, which in turn will make accessing, monitoring, and analyzing data to build solutions a lot easier.
Data-centric AI brings in bag full of benefits. Since this paradigm requires a deeper understanding of data, it can easily be integrated with the preprocessing of data, which usually takes up a massive amount of time in building a solution. As a result, the resource allocation for training in the Data-centric paradigm could be far less as it doesn’t require a lot of fine-tuning of hyperparameters. These are the benefits of Data-centric AI, to name a few.
Use Case Scenario: A Close Look at Data-Centric AI in Practice
Now let us look at how we can improve a model in the Data-centric paradigm. We will share here some of the learnings from the data-centric AI competition (to identify Roman numerals from images). For the competition, the participants were asked to alter training and validation datasets in such a way that the model resulting from it will have the best prediction accuracy on a hidden test dataset. For the sake of simplicity, let us imagine that we are building a model that classifies the images into cats and dogs. We need to pay attention to the following details.
- Ensure proper labeling according to well-defined guidelines e.g. Will the image be considered only if the full body of the animal is visible? Or just the head be enough? Does the animal have to be facing the camera?
- Ensure that all the images adhere to the same standards e.g., Should they be greyscaled or RGB? Should watermarks be allowed? What if the image contains both dogs and cats?
- Make sure that different subclasses are represented adequately both in the training and validation dataset e. g. how many different breeds of the species are present in the data? Are they distributed similarly in both training and validation datasets?
- Make sure that when resizing the image for input, relevant details are not lost. In other words, understand how much detail the model needs to learn to make better predictions? i.e., when the image is resized, examine how much information is lost. Does the model use the ears to identify the animal? Are they lost when resizing the image?
- Adding different data augmentations and ensuring that it does not lead to noise. For, e.g., horizontal, and vertical shifts may be suitable augmentations but not vertical flip. When horizontal/vertical shift is used, does it lead to the image losing relevant parts?
This brings up another question – how do we choose augmentations? There are a few guidelines on choosing the augmentations that can enrich the model.
- Try out individual augmentations and see how the performance varies. If some augmentations improve accuracy, that can help us to build a better model. These augmentations need not be applied to the whole dataset. Sometimes, it can improve the performance vis-a-vis a specific class.
- We need to have an idea of up to what degree an augmentation should be performed. Having too little and too much can be detrimental. We need to find the optimal amount of a particular augmentation or a combination of augmentations to get to the best solution.
- The augmented examples should be realistic where humans can also do well. If humans cannot succeed in identifying the augmented image, that becomes bad data.
Following these steps, the best way to improve model accuracy is to perform iterations of error analysis. This is one of the central parts of the data-centric paradigm. This process enables us to systematically improve the quality of the dataset. Starting with the original data, we built a baseline model. Using this model, we then examined the predictions on the validation and the test data. This helped us to understand the cases where the model does not predict correctly. Then we formulated different hypotheses that could have led to these failures. To test these hypotheses, we modified the original dataset:
a) By reconfiguring training and validation datasets
b) Implementing augmentations
Each time we cleaned the dataset after implementing augmentations. If any of these steps led to improvement in accuracy, (in other words validated our hypotheses) they were adopted to the dataset. If not, they were rejected. This feedback process was repeated several times, which led to not just better performance but also a better understanding of how the model works. As a result of this iterative error analysis, we could achieve a ~20% increase in accuracy (64.7% to 84.7%) on the hidden dataset.
Get Started From Here…!
Some of these lessons can be implemented in the case of structured datasets such as tabular data. For example, consider the case of customer data. While labeling, one needs to be clear of what and how data is to be collected. For that, proper planning is necessary. Then we can start with data selection. We should remove the data which does not have enough features as required. Also important is for data to have consistent formatting i.e., same date format, categorical labeling, number of decimal places, etc. Next, to ensure proper training/validation distribution, various considerations are necessary. For example, one should ensure similar distribution of high spenders and low spenders in both training and validation datasets. If not, this can lead to biases in the prediction. Next, we should understand how much detail the model requires to learn. For e.g., if we have a variable, what order of magnitude does it matter to make correct predictions (like in the range of 10s or 100s etc.). These are some examples.
Don’t Stop…, You’re One Step Closer to the Solution!
Despite all these efforts, these steps may still prove to be insufficient. As far as tabular data is concerned, feature engineering plays a key role. For example, it is possible that there are features that are not yet considered and have missing pieces of information. It is even possible that the current features, once represented in a different way, could also bring new insights to the model. This is especially important given performing the error analysis on the tabular data is quite different. In the case of unstructured data such as images, the Data Scientist can examine even a few hundred images. In the case of tabular data, the number of entries might range even up to tens of thousands.
Questions, Answered!
In the case of tabular data, another question that arises is the issue of outliers. They are not necessarily abnormal data but under-represented behavior. How can the AI solution address these scenarios? There could be two approaches to solving this issue. One way is to use different sampling methods to augment the data. This is comparatively easier. And the second way is to look for more data. This requires persistent monitoring but can yield better examples.
“Data-centric AI should not be just limited to data and algorithm; it should be an organizational attitude.”
Peeping In: All that an Organization Needs!
Preparing for a paradigm shift to Data-centric AI requires changes in not just the method of problem-solving but also in the organizational attitude. We recommend the following:
- Need to augment the Data-centric approach (which treats data as asset and applications as ephemeral) with the existing data-driven culture (which orients data in application-centric view)
- Appoint a chief data officer who shall be responsible to implement good data management practices
- Develop a data strategy for the collection, storage, and usage of data, at every step of the value chain with future potential also in mind
- Develop and implement policies for data quality and consistency
- Flexible and easy-to-use tools for accessing and processing different kinds of data
- Establish proper channels to communicate the results of research to the decision-makers and ensure their applications are in practice
- Increase the ease of using Data Science by having reusable, ready-to-use models and APIs and formal processes in place
- Put people who understand the data at the forefront; hire and cultivate new talents
Unleashing Data-Centric Power- MLOps and DataOps
To accommodate the Data-centric paradigm, we need to consider changes in every step of production. Hence it is essential to implement suitable good practices during MLOps and DataOps. While working with big industrial datasets, keeping track of different Data-centric models (or rather data distributions) can be quite difficult. The data subset we need to retrieve from the data storage to build and/or update models becomes an important aspect of developing the solution. Similarly, Data-centric AI prompts us to take a fresh look at the MLOps practices. It can require a closer inspection of data acquisition and feature engineering. The best practices are yet evolving and being explored.
However, the crucial prerequisite of Data-centric AI is that it demands higher quality data and a deeper understanding of the data over techniques. This points a greater involvement of subject matter experts who can largely simplify the building of the solution. Closer collaboration with the Data Scientists and analysts would be required to structure the problem in a better way, which in turn will help to understand how to approach the data.
Is It Still Point-Blank? Or End to all Data-Centric AI Confusion
There are certain new questions arising as we move to the new paradigm that has not yet been answered. For example, where do we draw the line between Data-centric AI and model-centric AI? At what point can we decide that Data-centric AI has done its best and we need to finetune the model hyperparameters? This can take us back to the drawing board to reformulate the problem or alter the definitions/principles on which the model is built. Nevertheless, at the end of the day, we would like to refrain from claims like Data-centric AI is the panacea to build high-quality models. What Data-centric AI asks for is a better quality of the data.
It brings the focus from techniques back to the understanding of the problem. And the problem can be understood well only if the data is good enough. No amount of fine-tuning can fix undefined data. But it does not mean that the model-centric approach is outdated. It also has its place. We can use the model’s fine-tuning techniques on top of the Data-centric AI approach to augment and enhance the solution approach.